




はじめに
こんにちはTyshiです。
前回の『Pythonでドバスポからカード画像を取得してみた【URL・HTML解析編】』にたくさんのいいね・リツイートをいただきありがとうございます。今回はその続編として、カード取得を実際のソースコードに落とし込んだのでその説明をしていきたいと思います。

出力結果
この後にソースコードの解説に移りますが、『Python 分からないからソースコードより結果が見たい』という方もいると思いますので先に結果を貼ります。出力結果は以下のように、各クラスごとに分けてカード画像が取得できました。「C_」から始まるカードは進化前フォロワー・スペル・アミュレット、「E_」から始まるカードは進化後フォロワーです。
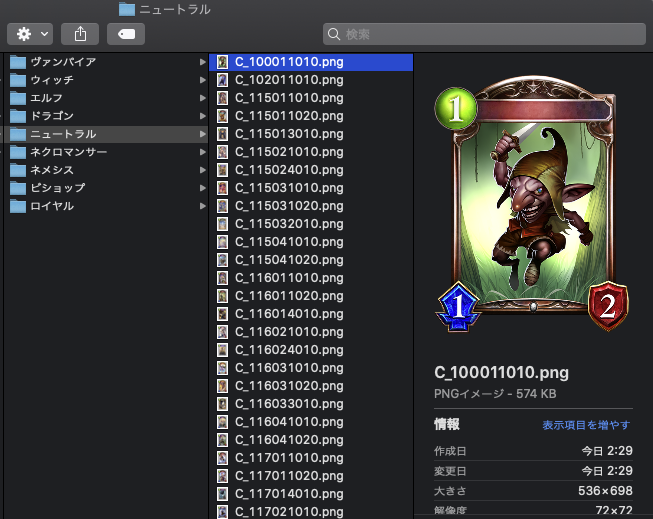
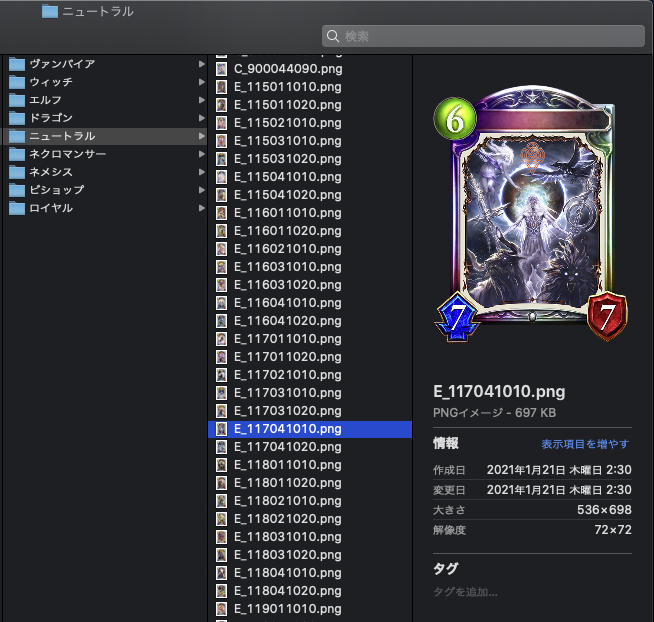
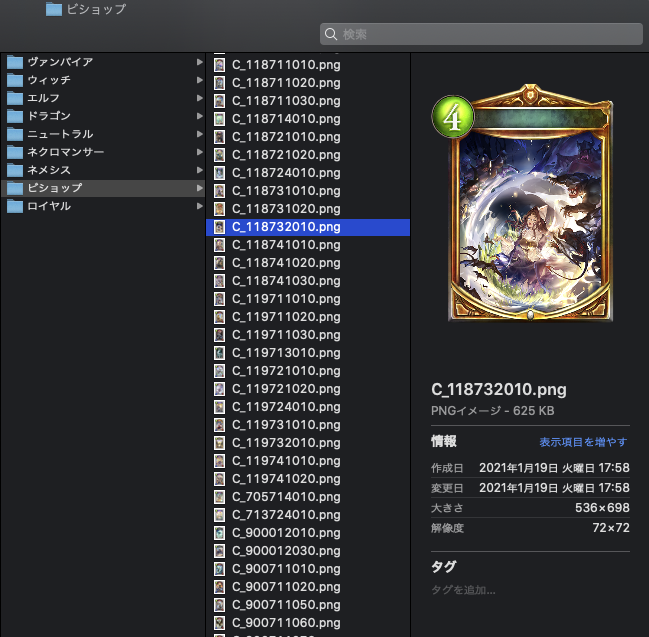
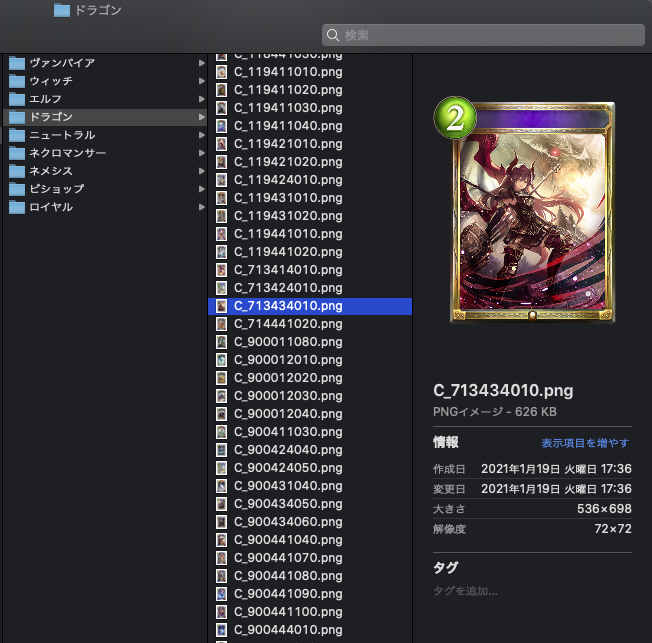
ソースコード解説
それではソースコードについて解説していきます。まずは処理順序のイメージを掴み続いてソースコード全体全量を把握、その後コードの要所にスポットを当てて解説していきます。
ちなみにコメント、整形のための改行合わせて86行程度で書くことができました。少ない行でコードを書くことができるのもPythonの魅力の一つですね。
処理順序とイメージ
ソースコードを見る前にまず処理順序とイメージを確認しましょう。回転している矢印はそれぞれの単位でループして処理を行なっていることを表しています。
処理順序
① クラス(エルフ、ロイヤル等)ごとに画像格納フォルダを作成② 各クラスの一覧ページにアクセスし、ページ内のカード詳細ページURLを取得
③ 詳細ページにアクセスし画像タグを抽出
④ 画像タグから画像ファイルの情報を抽出し画像を保存する
※ ③で取得した全ての画像タグごとに④処理を行う
⑤ ②に戻り、次のカードの詳細ページにアクセスし、③〜④の処理を行う
※ 各クラスが持っている全てのページで同様の処理を行う。
⑥ 次のクラスで同様に①〜⑤の処理を行い繰り返す。
イメージ図

ソースコードの説明
処理の流れを見ていただいたのでソースコードの説明に移りたいと思います。
# Shadowverse Portal からカード画像をダウンロードする
import time
import re
import requests
from pathlib import Path
from bs4 import BeautifulSoup
# ドバスポのURLを定数化(詳細ページURL作成で利用)
DETAIL_URL = 'https://shadowverse-portal.com'
# 1-1. 取得したいクラスをリスト化
clanlist = ['ニュートラル', 'エルフ', 'ロイヤル', 'ウィッチ', 'ドラゴン', 'ネクロマンサー', 'ヴァンパイア', 'ビショップ', 'ネメシス']
# 1-2.取得したいパックをリスト化
packlist = [‘10019’, ‘10018’, ‘10017’, ‘10016’, ‘10015’]
def main():
# 2.取得したいパックのURLを取得する(下に該当メソッドがあります)
cardset = cardlist_str()
# クラス単位でループさせる
for clan in range(len(clanlist)):
# clanlist[clan]に値があれば処理開始
if clanlist[clan] != '':
# 3.格納するフォルダを設定(存在しない場合は作成する)
output_folder = Path('シャドバ/' + str(clanlist[clan]))
output_folder.mkdir(exist_ok=True)
for i in range(10):
# 4.スクレイピングしたいURLを設定
org_url = 'https://shadowverse-portal.com/cards?m=index&lang=ja&clan%5B%5D=' + str(clan) + '&format=1'+ str(cardset) +'&atk=0&atk_operator=1&life=0&life_operator=1&type=0&card_offset='
url = org_url + str(i*12)
linklist = []
html = requests.get(url).text
soup = BeautifulSoup(html, 'lxml')
# 5.imgタグから詳細ページのURLをすべて取得し
# 変数linlistに格納する
a_list =soup.find_all('a', class_='el-card-visual-content')
for a in a_list:
# URLを抽出
link_url = a.attrs['href']
# URLをリストに追加
linklist.append(DETAIL_URL + link_url)
time.sleep(1.0)
# 6.各詳細ページから画像ファイルのURLを特定
# 画像ファイルを3で作成したフォルダに格納する
for page_url in linklist:
# 6-1.詳細ページのhtmlを取得
# imgタグをすべて取得しimg_listに格納
page_html = requests.get(page_url).text
page_soup = BeautifulSoup(page_html, "lxml")
img_list = page_soup.find_all('img')
for i, img in enumerate(img_list):
# 6-2.画像ファイルのURL,ファイル名を抽出
img_url = (img.attrs['src'])
filename = re.search(".*\/(E.*png.*|C.*png.*)$",img_url)
# 6-3.ファイル名が取得できた場合画像を保存する
if filename != None:
# 保存先のファイルパスを生成
save_path = output_folder.joinpath(get_left_words(filename.group(1), '?'))
time.sleep(1.0)
# 画像をダウンロード
try:
image = requests.get(img_url)
# 保存先のファイルパスにデータを保存
open(save_path, 'wb').write(image.content)
# 保存したファイル名を表示
print(save_path)
time.sleep(1.0)
except ValueError:
# 失敗した場合はエラー表示
print("Error!")
def cardlist_str():
# 2. 取得したいパックのURLを作成する。
cardset = ''
for i in range(len(packlist)):
cardset = cardset + '&card_set%5B%5D=' + packlist[i]
return cardset
def get_left_words(s, kugiri):
# 6-3.文字列sを区切り文字で区切り、もっとも左の文字を取得する。
return s.split(kugiri, 1)[0]
if __name__ == '__main__':
main()
スポットごとの説明(1.)
続いて数字ごとにスポットを当てて説明していきます。
# 1-1. 取得したいクラスをリスト化 clanlist = ['ニュートラル', 'エルフ', 'ロイヤル', 'ウィッチ', 'ドラゴン', 'ネクロマンサー', 'ヴァンパイア', 'ビショップ', 'ネメシス'] # 1-2.取得したいパックをリスト化 packlist = [‘10019’, ‘10018’, ‘10017’, ‘10016’, ‘10015’]
「1-1.」は取得したいクラスを、「1-2.」は取得したいパックをリスト化しています。これは 前回 の解析結果に基づいた順番で設定しています。
このリストをいじると、欲しいクラスだけ、欲しいパックだけとることができます。クラスをいじる際は取得しないクラスは「’’」シングルコーテーション2つだけ(クラス名を記載しない)にしておいてください。
・clan%5B%5D=:クラス
0:N, 1:E, 2:R, 3:W, 4:D, 5:Nc, 6:V, 7:B, 8:Nm・card_set%5B%5D=:カードパック
十天覚醒:10019
レヴィールの旋風:10018
運命の神々:10017
ナテラ崩壊:10016
アルティメットコロシアム:10015
スポットごとの説明(2.)
# 2.取得したいパックのURLを取得する(下に該当メソッドがあります)
cardset = cardlist_str()
def cardlist_str():
# 2. 取得したいパックのURLを作成する。
cardset = ''
for i in range(len(packlist)):
cardset = cardset + '&card_set%5B%5D=' + packlist[i]
return cardset
前回の記事より、URLをいじることで好きなパックの一覧にアクセスすることができることがわかっているので、取得したいパックのURLを生成します。『cardlist_str()』は関数(メソッド)と呼ばれるもので、処理を別に記載しているだけです。※何度も呼び出す可能性のある処理は関数化してあげると使い勝手が良くなります。今回は1回しか呼び出さないのであんまり意味ないです。。。
やっていることは変数『cardset』にパック部分のURLを文字列として格納しています。処理結果は以下のようになります。
# cardsetの値 '&card_set%5B%5D=10019&card_set%5B%5D=10018&card_set%5B%5D=10017&card_set%5B%5D=10016&card_set%5B%5D=10015'
スポットごとの説明(3.)
# 3.格納するフォルダを設定(存在しない場合は作成する)
output_folder = Path('シャドバ/' + str(clanlist[clan]))
output_folder.mkdir(exist_ok=True)
ここからの処理は『clanlist』の中に格納されている要素を一つずつ取り出して「clan」という変数に格納し、処理を行います。(変数「clan」の値は「0:N」から始まり、「8:Nm」に移り変わりながら9回処理されます。)
3.では、このプログラムを実行した場所の直下に「シャドバ」フォルダと「各クラス名」フォルダを作成します。取得したファイルはここに格納されます。
スポットごとの説明(4.)
# 4.スクレイピングしたいURLを設定 org_url = 'https://shadowverse-portal.com/cards?m=index&lang=ja&clan%5B%5D=' + str(clan) + '&format=1'+ str(cardset) +'&atk=0&atk_operator=1&life=0&life_operator=1&type=0&card_offset=' url = org_url + str(i*12) linklist = [] html = requests.get(url).text soup = BeautifulSoup(html, 'lxml')
ここからは一覧ページのページごとに処理を行います。
4.ではいよいよ一覧ページのURLを作成します。変数「org_url」はクラスを表す変数「clan」、カードパックを表す変数「cardset」を合体させURLを生成します。そして出来上がった「org_url」変数に取得したいページ数を付与して変数「url」とします。これで目的の一覧ページのURLが完成しました。
一覧ページのURL ※()は今回使用する変数名
https://shadowverse-portal.com/cards?m=index&lang=ja& [クラス(clan)] &format=1& [カードパック(cardset)] &atk=0&atk_operator=1&life=0&life_operator=1&type=0& [カードページ数(str(i*12))]
スポットごとの説明(5.)
# 5.imgタグから詳細ページのURLをすべて取得し
# 変数linlistに格納する
a_list =soup.find_all('a', class_='el-card-visual-content')
for a in a_list:
# URLを抽出
link_url = a.attrs['href']
# URLをリストに追加
linklist.append(DETAIL_URL + link_url)
time.sleep(1.0)
一覧ページのカード画像には詳細ページへのURLが含まれているのでそれを抽出し変数「link_url」に格納します。その後、格納した「link_url」はリスト「linklist」に追加します。カード全てから詳細ページのURLを抽出しリスト「linklist」に格納し終わるとこの部分の処理は終了です。
スポットごとの説明(6.)
6-1.
# 6.各詳細ページから画像ファイルのURLを特定
# 画像ファイルを3で作成したフォルダに格納する
for page_url in linklist:
# 6-1.詳細ページのhtmlを取得
# imgタグをすべて取得しimg_listに格納
page_html = requests.get(page_url).text
page_soup = BeautifulSoup(page_html, "lxml")
img_list = page_soup.find_all('img')
ここは各カードの詳細ページごとの処理を行います。この部分では詳細ページにアクセスし、「imgタグ」を全て取得しています。
6-2.
for i, img in enumerate(img_list):
# 6-2.画像ファイルのURL,ファイル名を抽出
img_url = (img.attrs['src'])
filename = re.search(".*\/(E.*png.*|C.*png.*)$",img_url)
ここは「imgタグ」ごとに処理を行います。この処理では「imgタグ」から画像のURLと画像ファイル名を取得します。
6-3.
# 6-3.ファイル名が取得できた場合画像を保存する
if filename != None:
# 保存先のファイルパスを生成
save_path=output_folder.joinpath(get_left_words(filename.group(1), '?'))time.sleep(1.0)
# 画像をダウンロード
try:
image = requests.get(img_url)
# 保存先のファイルパスにデータを保存
open(save_path, 'wb').write(image.content)
# 保存したファイル名を表示
print(save_path)
time.sleep(1.0)
except ValueError:
# 失敗した場合はエラー表示
print("Error!")
そして最後に、この処理で先程とってきた画像ファイルの情報を元にローカルフォルダに保存します。
改善点と今後について
結果を見ていただけるとわかりますが、各カードの名前が取得できていません。名前は別の画像として設定されており改善案として、別途取得しカード画像と合成する処理が必要になります。
また今後については前回の記事でも明言した、『新弾リリース後30分以内に新弾評価リストを作成できるプログラムを作りたい』を目標にカードリスト作成プログラムを作っていきたいと思います。
おわりに
ここまで読んでいただきありがとうございました。
Python やプログラミングに少しでも興味を持っていただけると嬉しいです。


コメント