




はじめに
こんにちはTyshiです。
皆様はShadowverseの新カードが発表されたときどのような気持ちになりますでしょうか。『絵柄はどうだろう』『どんな効果だろう』、『どんなフレーバーテキストだろう』とワクワクしますよね。チームに所属している人はカードの効果を見て新弾評価でワイワイするのも楽しみの一つと思います。
また、新弾発売の1ヶ月前位から続々と新カードの情報が開示され、デッキ考察に思いを馳せながらリリース日を迎えるのもとても楽しいですね。
しかしながらこの数弾、リリース前の時点ではレジェンド・ゴールド枠のカード情報程度しか開示されずリリース後にようやく全カードを知ることができるという状況になっています。
リリース直後、カード情報をいち早く確認するために、Shadowverse Portal (以降ドバスポ)を利用しているのではないかと思います。

ディティールモードがいい感じに見やすいのですが、カードごとの評価ができない。
そして、クラス別で見たい場合はいちいち検索する必要があるのでリスト化できていた方がいいのではないかと思いました。
有志の方が新弾評価リストを作成してくれるのを待つという方法もありますが、現状だと2〜3時間位くらいかかる。
そこで、以下を目標にプログラム作成を始めました。
『リリース後30分以内に新弾評価リストを作成できるプログラムを作りたい』
今回はその第一弾として、ドバスポからローテーションのカード画像を取得してみました。その過程であるURL・HTML解析を書きます。
プログラムソースの解説を公開しました。以下からご覧ください。

使用言語
Python
画像取得イメージ
以下の流れで取得
- URLで目的のカード一覧にアクセス
- 詳細画面のURLを全て抽出
- 詳細画面のURLにアクセスし、カード画像を取得する
- 1~3をクラスごと、一覧ページごとに繰り返す
※各カード毎に1種類のカード画像を取得するだけなら一覧ページだけでも事足りそうですが、今後の評価シート作成に利用する情報取得のためにも、詳細ページにアクセスできるようにしておいて損はないためこのような流れにしています。
URL解析
それではまずドバスポのURLを解析していきたいと思います。
ドバスポのカード一覧には検索項目があり、検索内容をURLに反映してアクセスしているため、これを解析すると好きなクラスの好きなページに飛ぶことができます。
例えば、『カードパック:十天覚醒』の『クラス:エルフ』のカードが見たい場合のURLは
『カードパック:十天覚醒、レヴィールの旋風』、『クラス:ロイヤル、ドラゴン』の2ページ目が見たい場合のURLは
と言った具合です。上記2つのURL比較だけでもクラスやカードパックがそれぞれどの部分を変えるといいかわかりますね。
以下に今回使用しそうな項目のURL解析結果を載せます。
URL解析結果
・card_name=:カード名
・clan%5B%5D=:クラス
0:N, 1:E, 2:R, 3:W, 4:D, 5:Nc, 6:V, 7:B, 8:Nm・format=:1:ローテ, 2:アンリミ
・card_set%5B%5D=:カードパック
十天覚醒:10019
レヴィールの旋風:10018
運命の神々:10017
ナテラ崩壊:10016
アルティメットコロシアム:10015・card_offset=:カード表示単位(1ページ12枚)
1ページ:0-11
2ページ:12-23
3ページ:24-35 …・char_type%5B%5D=:カードの種類
1:フォロワー
2:スペル
3:アミュレット
HTML解析(一覧ページ)
目的の一覧ページにアクセスできるようになったので次は各カードの詳細ページにアクセスできるようにします。
そのためにブラウザに標準装備されている開発ツールを利用してHTMLを解析していきます。
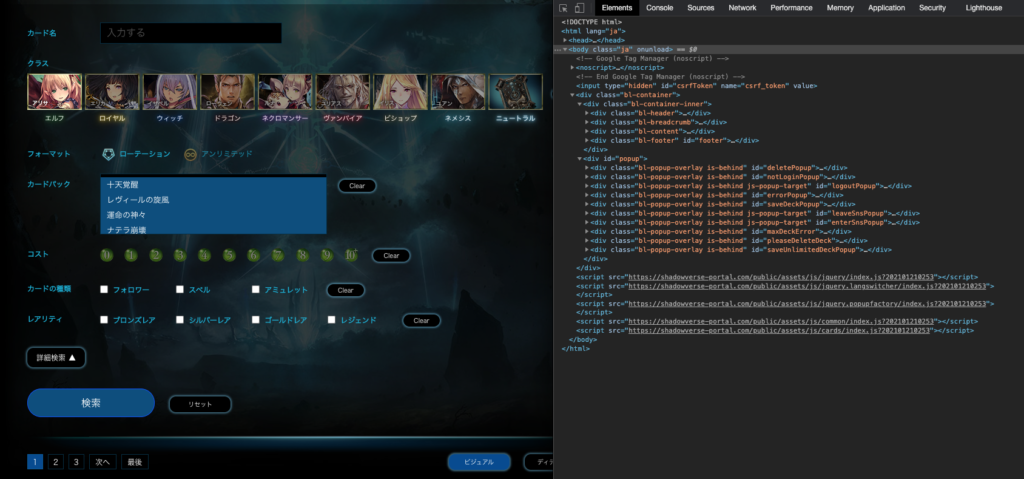
今回は詳細ページのURLだけが欲しいのであまり難しくはなさそうですね。
HTML解析のコツはとりあえず『id』、『class』、『tag』あたりを探しにいくことだと思います。
今回利用するであろう一覧ページの情報を以下に記載します。
カード詳細ページのURLを持つ class
el-card-visual-content
このclass属性はカード毎にあり、class属性で指定しリストとして取ってくるといいと思います。
取り出すときは、さっき取ってきたリストに対して、以下のように指定するとURLが取れそうです。
リスト[番号].href:詳細ページのURL
このURLを元に次項で詳細ページにアクセスし画像ファイルを取得したいと思います。
HTML解析(詳細ページ)
前項で取得したURLを元に、画像取得を行います。
今回取得したいのは画像のみなのでこれもそこまで難しくなさそうです。
画像を取得するためには画像の格納されているURLが必要です。これを保持している tag属性 を探しましょう。
画像情報(URL)を持つ tag
img
ここからカード画像のURLを抜き出すためには以下の属性を見れば良さそうです。
画像URLを持っている属性
src
ただし、注意しなければいけないのはimgタグはカードの画像だけでなく、ドバスポ詳細ページのリンク画像等にもついているためその画像は取得しないように設定しないといけません。
そこで、カードの画像URLにのみ記載されている文字を特定するために、URL解析を行います。
解析結果
共通部分
https://shadowverse-portal.com/img/card/phase2/common/カードの種類毎に共通部分の後ろのURLが変わる
・進化前フォロワー、スペル、アミュレット:
C/C_[カード毎の固有の番号].png?[接続日時?]・進化後フォロワー:
E/E_[カード毎の固有の番号].png?[接続日時?]
上記より、『C_』または『E_』から始まるかつ『.png』が含まれるURLを取得すれば良さそうですね。
まとめ
ここまで読んでいただきありがとうございます。今回は画像抽出に際してのURL・HTML解析を行いました。一部大雑把な記載があって分からない部分があるかもしれません。何か質問等ありましたら、管理人(Tyshi)のツイッター(@Tshi0709)に連絡いただけると幸いです。
次回はいよいよプログラムソースに書いて実際に動かしてみる部分を書きたいと思います。
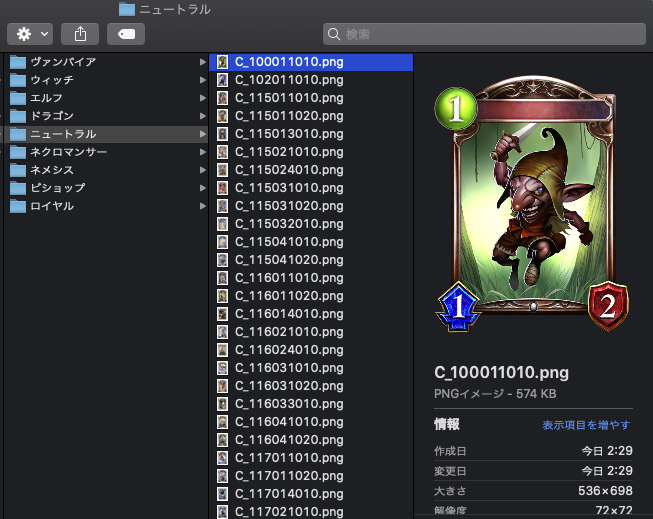
※ちなみに、結果をフライングすると実行結果は以下のような感じでいい具合に画像ファイルが取れました。


コメント